Designing Human + AI Systems for Digital Learning
Pilot initiative for Illinois Tech focused on scaling accessibility across 2000+ learning assets through Human + AI workflow orchestration and QA frameworks
Context
Illinois Tech had a large and growing library of instructional video content — and a compliance obligation to make it accessible through audio descriptions. Leadership saw AI as a way to close that gap without overwhelming staff.
I joined a cross-functional team that included instructional design, digital learning, Rubrient as the external AI vendor, and university leadership, including Jinhee Choo, Deputy Vice Provost for Online Learning, and Norma Scagnoli, Chief Learning Officer.
Together, we explored what it would take to integrate AI-generated audio descriptions into a university learning environment.
Snapshot
Role
Design Strategist
Timeline
~ 6 months
Project Type
Team
0→1 pilot strategy · Human + AI workflow design· Service model definition · Pilot evaluation
Instructional designer· AI vendor · Digital learning expert · Deputy Vice Provost for Online Learning
-
Highlights
Presented the work at the TeachX 2026 Conference, contributing to broader conversations on Human + AI accessibility workflows in higher education.
Core Challenge
Initial belief
The project began with a seemingly straightforward assumption: if AI could reliably detect visuals and generate descriptions, accessibility could be scaled with significantly less manual effort.
What changed?
As we explored the technology and content ecosystem, it became clear that generation was only part of the problem. The same visual could require different descriptions depending on the instructional context. Quality depended as much on context, review, and decision-making as it did on the AI itself.
This shifted the initiative from asking:
Can AI generate audio descriptions?
to
The real challenge
The challenge was no longer improving AI outputs alone. It was determining how instructional experts, reviewers, platform teams, technology partners, and leadership could work together to make those outputs trustworthy enough to review, evaluate, and eventually scale.
What operating model is required to make this trustworthy enough to scale?

A messy problem needed a messy workspace — paper notes, Post-its, and a lot of digital mapping.
My Role
My role was to help define the operating model around the AI capability: who was involved, how work should move, where human judgment was required, how AI outputs should be reviewed, and how the pilot should be evaluated.
Stakeholder Mapping
Workflow prototyping
Ecosystem Mapping
Evaluation framework
What I Did and Why Each Decision Mattered
Before defining processes, roles, or metrics, the team first needed to understand where AI could create value, where human expertise remained necessary, and what evidence leadership would require before investing further. My approach focused on answering those questions through a series of decisions:
Who needs to be aligned? → What system surrounds the service? → How should the work move? → How should humans make review decisions? → How should the pilot be evaluated before scale?
Each decision produced a clearer understanding of what would be required to move from an exploratory AI capability to a viable pilot.
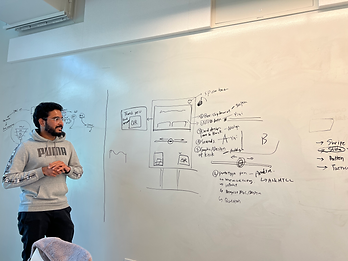
TYPOGRAPHY
Process snapshots from mapping, working meetings, and presentations that helped turn an AI idea into a structured pilot model.




Outcome
The Operating Model
System-level view of the operating model that defines how instructional context, AI generation, human review, governance, and evaluation work together as a single system. The model was used to align stakeholders, structure pilot implementation, and establish the conditions required for evaluating scalability across learning content.
This connected five pieces:

Role clarity

Technology Capability

Workflow Structure

Quality checks

Evaluation Framework
Where It Stands
-
Phase 1 is underway across 3 courses and 100 videos. The instructional value logic is in active use — reviewers are flagging visuals using the criteria I designed. Findings from Phase 1 will determine readiness for Phase 2 (~300 videos), building toward accessible coverage of 16,000+ assets.
-
What Phase 1 is doing right now is stress-testing that system against real content, real reviewers, and real institutional constraints.
-
The work was presented at TeachX 2026 at Northwestern University.
What I'd Take Further
-
I'd track the human edit rate by visual category — not just overall description quality. High edit rates on specific content types would feed directly back into retraining the AI model, turning the review process into a continuous improvement loop rather than a one-time quality check.
-
I'd also have defined the evaluation criteria before designing the workflow, not after. Defining success first would have let me test every workflow decision against what the institution was actually trying to optimise for — rather than designing the system and then asking how to evaluate it.
Key Learnings
1. The technology was the least complicated part.
The AI capability was available from day one. What took six months to design was the system of people, decisions, criteria, and governance that made it usable. The workflow was the real product.
2. Mapping complexity is not preliminary work — it is the work
The stakeholder and ecosystem maps didn't just inform the design. They made design possible. The workflow could only be built because the constraints were visible first.
3. Criteria need to work without you in the room.
A reviewer in month three, working through video number 80, needs to apply the instructional value logic without having been in the original design conversation. Designing for that kind of portability — for handoff, not just for the immediate pilot — was one of the harder problems.